k-Means Algorithm#
The EM algorithm for k-means has the following procedure:
Guess some initial cluster centres.
Repeat the following until convergence is reached:
E-step: Assign points to the nearest cluster centre.
M-step: Update the cluster centres with the mean position.
The E-step updates our expectation of which cluster each point belongs to, while the M-step maximises some fitness function that defines the cluster centre locations. Each repetition of the E-M loop will always result in a better estimate of the cluster characteristics.
Let’s write some code to perform this algorithm ourselves.
First, we need some data to cluster; for this, we will use the scikit-learn method to produce random blobs of data.
import numpy as np
import matplotlib.pyplot as plt
X = np.loadtxt('../data/kmeans.txt')
fig, ax = plt.subplots(figsize=(6, 4))
ax.plot(X[:, 0], X[:, 1], '.')
plt.show()
We will try to identify four clusters in this data. Therefore, we set the following.
n_clusters = 4
As a starting position, let’s select four of the points randomly.
import numpy as np
i = np.random.randint(0, X.shape[0], size=4)
centres = X[i]
Our initial guess is shown below with orange squares.
fig, ax = plt.subplots(figsize=(6, 4))
ax.plot(X[:, 0], X[:, 1], '.')
ax.plot(centres[:, 0], centres[:, 1], 's')
plt.show()
It is clear that they do not represent the arithmetic mean of any data.
The second step (the first of the E-M loop) assigns all the points to their nearest cluster centre.
This can be achieved very efficiently by using NumPy and array broadcasting.
First, we compute the vector from each of the data, X, to each current cluster centre.
vectors = X[:, np.newaxis] - centres
vectors.shape
(300, 4, 2)
Notice that the shape of this array is (number_of_data, number_of_clusters, dimensions).
The magnitude of the vector can describe the distance from the data to the current centres; we want the magnitude along the dimensions axis of the array (the final axis, hence -1).
magnitudes = np.linalg.norm(vectors, axis=-1)
magnitudes.shape
(300, 4)
We now have the magnitude of the vector from each data point to each cluster centre.
We want to know which centre each datapoint is closest to; we can use the argmin() method of the NumPy array.
This returns the index of the minimum value (the method min() will return the actual value, but we aren’t interested in this).
The argmin() method should only be run on the number of clusters axis to end up with an array of 300 indices.
labels = magnitudes.argmin(axis=1)
print(labels)
[3 0 0 0 3 2 1 0 0 0 1 1 0 1 2 3 0 2 3 3 2 2 0 1 1 1 2 3 1 3 0 1 0 3 1 1 1
1 1 2 3 1 3 0 1 3 0 1 0 2 1 2 0 2 3 3 0 3 1 2 1 3 0 3 1 3 1 2 1 1 0 3 0 1
1 0 1 0 2 0 2 3 2 2 0 0 2 3 1 0 3 2 1 1 3 3 2 2 0 1 0 2 0 2 0 2 2 0 3 0 3
1 2 1 2 0 1 2 3 0 3 2 3 2 3 2 2 1 2 1 0 1 1 2 3 3 1 1 3 0 1 3 3 1 0 1 3 3
0 1 0 0 3 3 2 3 0 1 2 0 1 3 3 3 0 1 2 3 2 3 3 0 2 0 3 0 3 2 3 3 2 0 1 1 3
0 0 3 2 1 3 3 0 3 1 1 1 3 1 1 3 3 2 1 3 1 1 0 0 3 0 1 3 0 0 3 3 2 2 3 1 2
2 1 2 1 3 0 0 0 3 0 3 2 3 3 2 3 0 1 2 3 2 1 0 1 1 1 3 3 0 1 2 3 1 1 3 2 2
0 0 3 1 2 0 3 3 0 0 2 2 1 1 0 0 2 3 0 0 1 2 2 3 2 2 2 1 3 0 3 2 2 0 0 0 3
2 3 0 1]
This array, labels, assigns each data point to the closest cluster centres, completing the E-step in the E-M loop.
Now, we need to update the cluster centres with the new arithmetic mean of the assigned data.
The data can be split into groups using logical slicing i.e., to get all values with the label 0.
X[labels == 0]
array([[-1.52392631, 7.12573205],
[ 1.27450825, 5.63017322],
[-0.86552334, 7.80121774],
[ 1.70536064, 4.43277024],
[ 0.4906169 , 8.82985441],
[-0.3529955 , 9.21042408],
[ 1.42013331, 4.63746165],
[ 1.1312175 , 4.68194985],
[ 0.57309313, 5.5262324 ],
[-0.02338521, 7.90031612],
[ 2.47034915, 4.09862906],
[ 1.92352205, 4.14877723],
[-1.46520534, 8.28085327],
[-1.6329012 , 7.39162392],
[-0.65837595, 7.47160121],
[ 0.76300091, 7.79086459],
[-1.75107248, 10.2479137 ],
[ 1.5528609 , 4.09548857],
[-0.89647566, 8.21469555],
[-0.47684983, 8.86489884],
[ 1.33263648, 5.0103605 ],
[-0.89349808, 8.45234657],
[-0.7495655 , 8.88343217],
[ 0.90802847, 6.01713005],
[-1.59570643, 7.25419154],
[-0.19685333, 6.24740851],
[-0.14797144, 9.13348199],
[-0.30578766, 7.56786527],
[ 1.10318217, 4.70577669],
[ 1.59034945, 5.225994 ],
[ 0.9867701 , 6.08965782],
[ 2.85942078, 2.95602827],
[ 0.11504439, 6.21385228],
[ 0.26507231, 8.38859208],
[-0.06687717, 7.20355626],
[ 2.46452227, 6.1996765 ],
[-1.00613781, 6.94673976],
[-1.6874453 , 8.01679844],
[ 0.94808785, 4.7321192 ],
[-0.70494388, 8.27450297],
[ 1.18454506, 5.28042636],
[ 0.70826671, 5.10624372],
[-1.21125005, 8.60336242],
[ 2.50904929, 5.7731461 ],
[-1.0843272 , 7.93178137],
[ 2.15504965, 4.12386249],
[ 1.7373078 , 4.42546234],
[ 1.12031365, 5.75806083],
[ 1.0427873 , 4.60625923],
[-0.31151331, 9.24778772],
[ 1.14294357, 4.93881876],
[ 1.64856484, 4.71124916],
[ 2.20656076, 5.50616718],
[-1.50990122, 7.65321523],
[ 0.0708811 , 6.9530412 ],
[-1.04895558, 7.78485647],
[ 2.89921211, 5.78430212],
[-1.4902756 , 9.35372119],
[-0.9639761 , 9.5781288 ],
[-1.71828866, 7.61872855],
[ 3.35941485, 5.24826681],
[-1.45115262, 7.72557724],
[ 0.87305123, 4.71438583],
[-0.11966171, 8.33146096],
[-0.15190893, 7.60124421],
[ 0.54111653, 6.15305106],
[ 3.2460247 , 2.84942165],
[ 4.21850347, 2.23419161],
[ 2.84382904, 5.20983199],
[-1.23962788, 8.36246422],
[-1.37930979, 8.9685399 ],
[-1.03477573, 6.62688636],
[-1.92628156, 9.13330581],
[-1.29395974, 8.05596767],
[ 1.44796828, 7.76153535]])
Above are all the datapoints associated with the first cluster centre, and the mean (along the datapoint axis can be found as).
X[labels == 0].mean(axis=0)
array([0.34528672, 6.66154321])
And it is possible to perform this for all four clusters with simple list comprehension.
new_centres = np.array([X[labels == i].mean(axis=0) for i in range(n_clusters)])
The new centres can be visualised below (this time with triangles).
fig, ax = plt.subplots(figsize=(6, 4))
ax.plot(X[:, 0], X[:, 1], '.')
ax.plot(centres[:, 0], centres[:, 1], 's')
ax.plot(new_centres[:, 0], new_centres[:, 1], '^')
plt.show()
Finally, we overwrite the centres object to update the centres.
centres = new_centres
This process should be completed until the centres do not change so we can use an iterative approach. See the code cell below, which loops over this process until there is no change in the centres.
from sklearn.datasets import make_blobs
import numpy as np
X, y_true = make_blobs(n_samples=300, centers=4, cluster_std=1, random_state=1)
n_clusters = 4
i = np.random.randint(0, X.shape[0], size=n_clusters)
centres = X[i]
diff = np.inf
while np.sum(diff) > 0.00000001:
vectors = X[:, np.newaxis] - centres
magnitudes = np.linalg.norm(vectors, axis=-1)
labels = magnitudes.argmin(axis=1)
new_centres = np.array([X[labels == i].mean(axis=0) for i in range(n_clusters)])
diff = np.abs(centres - new_centres)
centres = new_centres
We show the results below, with the different clusters identified by colour and the cluster centres marked with a black square.
from sklearn.cluster import KMeans
fig, ax = plt.subplots(figsize=(6, 4))
for i in range(n_clusters):
ax.plot(X[labels == i][:, 0], X[labels == i][:, 1], '.')
ax.plot(centres[:, 0], centres[:, 1], 'ks')
plt.show()
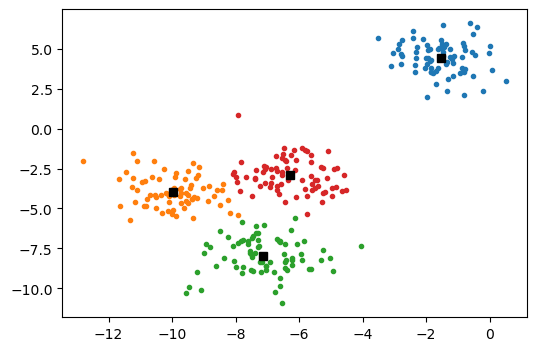
There are some important issues that one should be aware of in using the simple E-M algorithm discussed above:
The optimal result may never be achieved globally. As with all optimisation routines, although the result is improving, it may not be moving to the globally optimal solution.
k-means is limited to linear cluster boundaries. The fact that k-means finds samples as close as possible in cartesian space means that the clustering cannot have more complex geometries.
k-means can be slow for a large number of samples. Each iteration must access every point in the dataset (and in our implementation, it accesses each point
n_clustersnumber of times)!The number of clusters must be selected beforehand. We must have some a priori knowledge about our dataset to apply a k-means clustering effectively.
This final point is a common concern in k-means clustering and other clustering algorithms. Therefore, let’s look at a popular tool used to find the “correct” number of clusters.