Using PyMC
PyMC is a very powerful Python library designed for probabilistic and Bayesian analysis.
Here, we show that PyMC can be used to perform the same likelihood sampling that we previously wrote our own algorithm for.
Below, we read in the data and build the model.
The next step is to construct the PyMC sampler.
The format that PyMC expects can be a bit unfamiliar.
First we create objects for the two parameters, these are bounded so \(0 \leq k < 1\) and \(0 \leq [A]_0 < 10\) .
Strictly, these are prior probabilities tune
Unlike the code that we created previously, PyMC defaults to using the NUTS sampler, which stands for No-U-Turn sampler [7 ] .
This sampler enables the step size tuning that we have taken advantage of.
This results in a object assigned to the variable trace
posterior
<xarray.Dataset> Size: 168kB
Dimensions: (chain: 10, draw: 1000)
Coordinates:
* chain (chain) int64 80B 0 1 2 3 4 5 6 7 8 9
* draw (draw) int64 8kB 0 1 2 3 4 5 6 7 ... 993 994 995 996 997 998 999
Data variables:
k (chain, draw) float64 80kB 0.1009 0.1108 0.1124 ... 0.109 0.1041
A0 (chain, draw) float64 80kB 7.224 7.919 7.703 ... 7.397 7.397 7.726
Attributes:
created_at: 2026-03-16T15:31:37.907284+00:00
arviz_version: 0.23.4
inference_library: pymc
inference_library_version: 5.20.0
sampling_time: 4.441580295562744
tuning_steps: 1000
sample_stats
<xarray.Dataset> Size: 1MB
Dimensions: (chain: 10, draw: 1000)
Coordinates:
* chain (chain) int64 80B 0 1 2 3 4 5 6 7 8 9
* draw (draw) int64 8kB 0 1 2 3 4 5 ... 995 996 997 998 999
Data variables: (12/17)
perf_counter_start (chain, draw) float64 80kB 925.5 925.5 ... 929.1
lp (chain, draw) float64 80kB -3.46 -3.685 ... -3.636
diverging (chain, draw) bool 10kB False False ... False False
step_size (chain, draw) float64 80kB 0.7504 0.7504 ... 0.4382
smallest_eigval (chain, draw) float64 80kB nan nan nan ... nan nan
perf_counter_diff (chain, draw) float64 80kB 0.0003463 ... 0.0002055
... ...
max_energy_error (chain, draw) float64 80kB 0.4953 0.07306 ... -0.1664
process_time_diff (chain, draw) float64 80kB 0.0003461 ... 0.0002056
step_size_bar (chain, draw) float64 80kB 0.6206 0.6206 ... 0.6283
acceptance_rate (chain, draw) float64 80kB 0.8274 0.9738 ... 1.0
energy (chain, draw) float64 80kB 4.695 3.913 ... 3.776
tree_depth (chain, draw) int64 80kB 3 3 3 3 3 2 ... 2 2 1 2 1 2
Attributes:
created_at: 2026-03-16T15:31:37.928487+00:00
arviz_version: 0.23.4
inference_library: pymc
inference_library_version: 5.20.0
sampling_time: 4.441580295562744
tuning_steps: 1000 Dimensions: Coordinates: (2)
Data variables: (17)
perf_counter_start
(chain, draw)
float64
925.5 925.5 925.5 ... 929.1 929.1
array([[925.49854487, 925.49896137, 925.49939468, ..., 925.81094481,
925.81121102, 925.81162426],
[925.40511884, 925.40543225, 925.40577795, ..., 925.84521395,
925.84551864, 925.84601574],
[926.26429382, 926.26454685, 926.26513152, ..., 926.57866021,
926.57889693, 926.57933208],
...,
[927.88394658, 927.88435519, 927.88466949, ..., 928.21007115,
928.21047286, 928.21087967],
[928.70537275, 928.70575723, 928.70598189, ..., 929.12452202,
929.12477786, 929.12494204],
[928.75362302, 928.75387617, 928.75412902, ..., 929.05452418,
929.05476374, 929.0549099 ]]) lp
(chain, draw)
float64
-3.46 -3.685 ... -3.722 -3.636
array([[-3.45957624, -3.68467004, -3.55019841, ..., -3.8063508 ,
-3.94698387, -4.28064824],
[-3.47980355, -4.2221036 , -3.39749247, ..., -4.18392124,
-3.47161931, -3.53875078],
[-3.26816269, -3.35330883, -3.46738908, ..., -3.84912359,
-5.66344868, -6.95262249],
...,
[-3.60436481, -3.34670632, -3.73325021, ..., -4.00543588,
-3.73738125, -3.94490881],
[-4.47710715, -3.79953759, -3.82720361, ..., -3.69296447,
-3.69296447, -3.34700457],
[-3.54049558, -3.28950859, -3.67698582, ..., -3.72230613,
-3.72230613, -3.63642588]]) diverging
(chain, draw)
bool
False False False ... False False
array([[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
...,
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False]]) step_size
(chain, draw)
float64
0.7504 0.7504 ... 0.4382 0.4382
array([[0.75036166, 0.75036166, 0.75036166, ..., 0.75036166, 0.75036166,
0.75036166],
[0.76419882, 0.76419882, 0.76419882, ..., 0.76419882, 0.76419882,
0.76419882],
[0.70648743, 0.70648743, 0.70648743, ..., 0.70648743, 0.70648743,
0.70648743],
...,
[0.68978684, 0.68978684, 0.68978684, ..., 0.68978684, 0.68978684,
0.68978684],
[0.79756076, 0.79756076, 0.79756076, ..., 0.79756076, 0.79756076,
0.79756076],
[0.43820205, 0.43820205, 0.43820205, ..., 0.43820205, 0.43820205,
0.43820205]]) smallest_eigval
(chain, draw)
float64
nan nan nan nan ... nan nan nan nan
array([[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
...,
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan]]) perf_counter_diff
(chain, draw)
float64
0.0003463 0.0003685 ... 0.0002055
array([[3.46267000e-04, 3.68472000e-04, 3.59357000e-04, ...,
1.99557000e-04, 3.52422000e-04, 1.76885000e-04],
[2.33663000e-04, 2.75520000e-04, 2.08545000e-04, ...,
2.32173000e-04, 4.08664000e-04, 4.47808000e-04],
[1.65772000e-04, 5.03329000e-04, 2.37201000e-04, ...,
1.77738000e-04, 3.70948000e-04, 1.79757000e-04],
...,
[3.01544000e-04, 2.35077000e-04, 2.84873000e-04, ...,
3.39314000e-04, 3.45675000e-04, 1.96207000e-04],
[3.03940000e-04, 1.51228000e-04, 2.86323000e-04, ...,
1.87487000e-04, 9.63460000e-05, 3.65602000e-04],
[1.88209000e-04, 1.88801000e-04, 2.64895000e-04, ...,
1.79186000e-04, 9.08330001e-05, 2.05522000e-04]]) energy_error
(chain, draw)
float64
-0.1269 0.04513 ... 0.0 -0.0457
array([[-0.12691906, 0.04512783, -0.0120943 , ..., -0.14260475,
0.03304585, 0.2511468 ],
[-0.17851304, 0.24124132, -0.31270095, ..., 0.09847746,
0.1470623 , 0.01911356],
[ 0. , 0.01042302, 0.01499749, ..., 0.01893201,
0.32327253, 0.29840082],
...,
[-0.2457715 , -0.01565979, -0.03992221, ..., 0.45027142,
-0.11055096, 0.07391774],
[ 0.31926099, -0.26087719, -0.09628611, ..., -0.08977447,
0. , 0.03629987],
[-1.41948294, -0.04489311, -0.04806032, ..., -0.19524909,
0. , -0.0457038 ]]) reached_max_treedepth
(chain, draw)
bool
False False False ... False False
array([[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
...,
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False]]) largest_eigval
(chain, draw)
float64
nan nan nan nan ... nan nan nan nan
array([[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
...,
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan]]) index_in_trajectory
(chain, draw)
int64
-2 -3 2 -1 0 1 -2 ... -3 2 1 2 0 2
array([[-2, -3, 2, ..., 1, -2, -2],
[ 1, -1, -1, ..., 2, 2, -7],
[ 0, 2, -1, ..., -2, -2, 2],
...,
[-1, 2, -2, ..., 3, -6, 2],
[-2, -1, -1, ..., 2, 0, -2],
[ 1, -1, -2, ..., 2, 0, 2]]) n_steps
(chain, draw)
float64
7.0 7.0 7.0 7.0 ... 1.0 3.0 1.0 3.0
array([[7., 7., 7., ..., 3., 7., 3.],
[3., 5., 3., ..., 3., 5., 7.],
[1., 7., 3., ..., 3., 7., 3.],
...,
[3., 3., 3., ..., 7., 7., 3.],
[3., 1., 3., ..., 3., 1., 7.],
[3., 3., 5., ..., 3., 1., 3.]]) max_energy_error
(chain, draw)
float64
0.4953 0.07306 ... 1.056 -0.1664
array([[ 0.49533422, 0.0730625 , -0.0544323 , ..., -0.14260475,
0.4063295 , 0.85350085],
[-0.17851304, 0.32528539, -0.31270095, ..., 0.29979059,
0.48987305, -0.10924998],
[ 1.6653049 , 0.06868939, 0.01499749, ..., 1.46911178,
1.29538649, 0.39833362],
...,
[-0.2457715 , 0.02579192, 1.03397483, ..., 0.6269749 ,
0.43900238, -0.13506153],
[ 1.10114529, -0.26087719, -0.09628611, ..., 0.17881055,
0.05605753, 0.17050365],
[-1.41948294, -0.04489311, 0.5842328 , ..., 0.2979145 ,
1.05573623, -0.1663876 ]]) process_time_diff
(chain, draw)
float64
0.0003461 0.0003687 ... 0.0002056
array([[3.46090e-04, 3.68714e-04, 3.59471e-04, ..., 1.99790e-04,
3.52420e-04, 1.76962e-04],
[2.33622e-04, 2.75823e-04, 2.08652e-04, ..., 2.32424e-04,
4.09107e-04, 4.48290e-04],
[1.65815e-04, 5.03652e-04, 2.37670e-04, ..., 1.77769e-04,
3.71235e-04, 1.79729e-04],
...,
[3.01695e-04, 2.35374e-04, 2.85312e-04, ..., 3.39292e-04,
3.45761e-04, 1.96178e-04],
[3.04214e-04, 1.51585e-04, 2.86750e-04, ..., 1.87720e-04,
9.64320e-05, 3.65949e-04],
[1.88043e-04, 1.88792e-04, 2.64967e-04, ..., 1.79236e-04,
9.09880e-05, 2.05576e-04]]) step_size_bar
(chain, draw)
float64
0.6206 0.6206 ... 0.6283 0.6283
array([[0.62059665, 0.62059665, 0.62059665, ..., 0.62059665, 0.62059665,
0.62059665],
[0.68036292, 0.68036292, 0.68036292, ..., 0.68036292, 0.68036292,
0.68036292],
[0.70143002, 0.70143002, 0.70143002, ..., 0.70143002, 0.70143002,
0.70143002],
...,
[0.62161924, 0.62161924, 0.62161924, ..., 0.62161924, 0.62161924,
0.62161924],
[0.6472511 , 0.6472511 , 0.6472511 , ..., 0.6472511 , 0.6472511 ,
0.6472511 ],
[0.62832373, 0.62832373, 0.62832373, ..., 0.62832373, 0.62832373,
0.62832373]]) acceptance_rate
(chain, draw)
float64
0.8274 0.9738 1.0 ... 0.3479 1.0
array([[0.82739795, 0.97384334, 1. , ..., 1. , 0.82622869,
0.56874381],
[1. , 0.80483783, 1. , ..., 0.84822298, 0.83920811,
0.99344309],
[0.18913298, 0.96758527, 0.99278343, ..., 0.49094759, 0.46358667,
0.74008345],
...,
[1. , 0.98330203, 0.57325083, ..., 0.73399652, 0.86171381,
0.97624936],
[0.51136051, 1. , 1. , ..., 0.90469197, 0.94548474,
0.90826816],
[1. , 0.99437306, 0.77527233, ..., 0.86426396, 0.34793617,
1. ]]) energy
(chain, draw)
float64
4.695 3.913 3.69 ... 5.188 3.776
array([[4.69521129, 3.91311123, 3.69009732, ..., 4.11218771, 4.64772506,
5.59856955],
[3.8296997 , 5.09323535, 3.96472142, ..., 4.35722752, 4.8784704 ,
3.70284243],
[4.86260059, 3.53873711, 3.48722688, ..., 5.85703637, 7.14436882,
7.33864836],
...,
[4.53751455, 3.62272336, 4.75193538, ..., 5.53063511, 5.03620331,
4.07729239],
[5.81944783, 4.38132431, 4.20912313, ..., 3.94161802, 3.80886418,
4.00048189],
[5.53107835, 3.73801699, 4.41512759, ..., 4.55424671, 5.18822719,
3.77635319]]) tree_depth
(chain, draw)
int64
3 3 3 3 3 2 2 1 ... 2 2 2 2 1 2 1 2
array([[3, 3, 3, ..., 2, 3, 2],
[2, 3, 2, ..., 2, 3, 3],
[1, 3, 2, ..., 2, 3, 2],
...,
[2, 2, 2, ..., 3, 3, 2],
[2, 1, 2, ..., 2, 1, 3],
[2, 2, 3, ..., 2, 1, 2]]) Attributes: (6)
created_at : 2026-03-16T15:31:37.928487+00:00 arviz_version : 0.23.4 inference_library : pymc inference_library_version : 5.20.0 sampling_time : 4.441580295562744 tuning_steps : 1000
observed_data
<xarray.Dataset> Size: 80B
Dimensions: (At_dim_0: 5)
Coordinates:
* At_dim_0 (At_dim_0) int64 40B 0 1 2 3 4
Data variables:
At (At_dim_0) float64 40B 6.23 3.76 2.6 1.85 1.27
Attributes:
created_at: 2026-03-16T15:31:37.933018+00:00
arviz_version: 0.23.4
inference_library: pymc
inference_library_version: 5.20.0
This contains the chain information amoung other things.
Instead of probing into the trace arviz
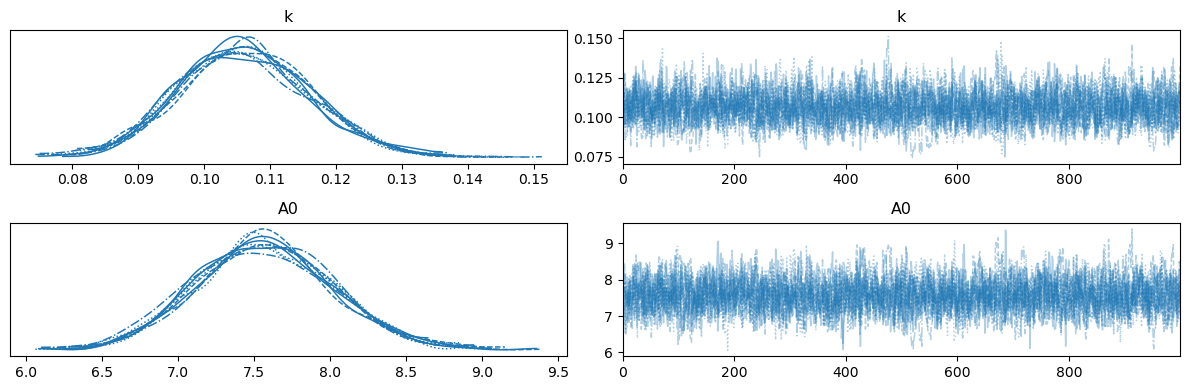
Above, we can see the trace of each of the different chains.
The chains appear to have converged to the same distribution.
We can get the flat chains with the following function.
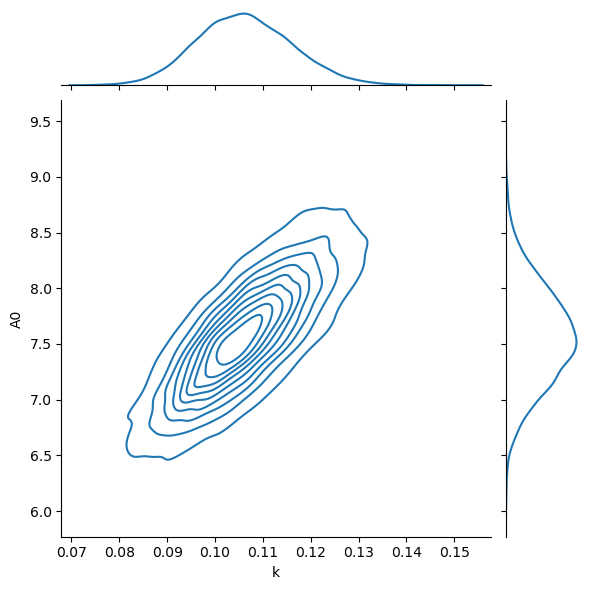
It is clear that, using PyMC, we have much better sampling of the distributions.
This makes using summary statistics, like the mean and standard deviation much more reliable.
mean
sd
hdi_3%
hdi_97%
mcse_mean
mcse_sd
ess_bulk
ess_tail
r_hat
k
0.106
0.01
0.088
0.125
0.000
0.000
2799.0
3562.0
1.0
A0
7.572
0.45
6.716
8.397
0.009
0.006
2729.0
3228.0
1.0